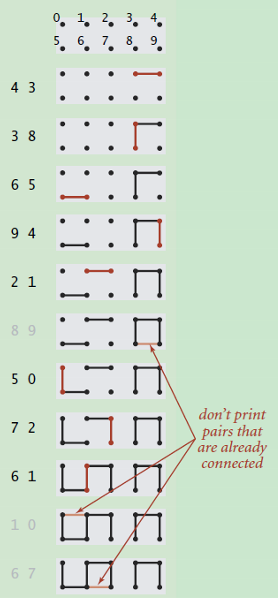
用于归类,判断动态连通性的一种概念。比如下面 0-9 个点,归并(4,3)即认为 4和3 同组(或者连通)。一波 归并 操作之后,查看某两个点是否连通(同组)。http://blog.jobbole.com/108359/
实现思路:
group_id 理论上可以是任何值,讨论的时候直接就给了元素本身的值(默认每个元素都是不一样的哈)。当为一个节点的时候,可以使用本节点的指针即 address 作为 group_id 。貌似后者应用型更强啊,所以下面我写的这个例子是后者。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #ifndef _U_FIND_SET #define _U_FIND_SET typedef struct { int s32Data; unsigned long s32GroupId; }stNode; void createNode (stNode **ppNode,int data) void destroyNode (stNode *pNode) unsigned long findGroupId (stNode *pNode) void unionNode (stNode *x,stNode *y) int getGroupCnt () #endif
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 #include <stdio.h> #include <stdlib.h> #include <string.h> #include <time.h> #include "uFindSet.h" static int group_count=0 ;void createNode (stNode **ppNode,int data) stNode *p = NULL ; if (!ppNode) return ; *ppNode = NULL ; p = (stNode *)malloc (sizeof (stNode)); if (!p) return ; p->s32Data = data; p->s32GroupId = (unsigned long )p; *ppNode = p; group_count++; } void initNode (stNode *pNode,int data) if (!pNode) return ; pNode->s32Data = data; pNode->s32GroupId = (unsigned long )pNode; group_count++; } void destroyNode (stNode *pNode) if (!pNode) return ; free (pNode); } unsigned long findGroupId (stNode *pNode) if (!pNode) return -1 ; if ( pNode->s32GroupId != (unsigned long )pNode ) { pNode->s32GroupId = findGroupId((stNode *)(pNode->s32GroupId)); } return pNode->s32GroupId; } void unionNode (stNode *x,stNode *y) unsigned long g_x = findGroupId(x); unsigned long g_y = findGroupId(y); if (g_x != g_y) { ((stNode *)g_x)->s32GroupId = g_y; group_count--; } } int getGroupCnt () return group_count; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 #include <stdio.h> #include <stdlib.h> #include <string.h> #include <time.h> #include "uFindSet.h" #define U_FIND_SET_NUM 10000 int uFindSet_test () int i; stNode *abc[U_FIND_SET_NUM]={0 }; srand(0 ); printf (" init group id \n" ); for (i=0 ;i<U_FIND_SET_NUM;i++) { createNode(&abc[i],i); } printf (" elem and their group\n" ); for (i=0 ;i<U_FIND_SET_NUM;i++) { unsigned long tmpid = findGroupId(abc[i]); printf ("<init>element %d, group_id is %lu(%d))\n" ,i,tmpid,((stNode *)tmpid)->s32Data ); } printf (" union some data randomly\n" ); for (i=0 ;i<U_FIND_SET_NUM;i++) { int a = rand()%U_FIND_SET_NUM; int b = rand()%U_FIND_SET_NUM; printf ("union %d and %d\n" ,a,b); unionNode(abc[a],abc[b]); } printf (" elem and their group \n" ); for (i=0 ;i<U_FIND_SET_NUM;i++) { unsigned long tmpid = findGroupId(abc[i]); printf ("<after>element %d, group_id is %lu(%d))\n" ,i,tmpid,((stNode *)tmpid)->s32Data ); } printf ("group_count %d\n" ,getGroupCnt()); for (i=0 ;i<U_FIND_SET_NUM;i++) { destroyNode(abc[i]); abc[i] = NULL ; } return 0 ; }